
배경
지금까지 엑셀 생성 기능을 두 차례 개선했습니다.
먼저 BlockingQueue를 활용해 이미지 다운로드를 병렬화했습니다. 순차 처리에서 병렬 처리로 전환하면서 다운로드 응답 시간을 단축했고 메모리 사용량도 제어할 수 있었습니다.
이어서 파일 생성을 비동기 스레드에서 수행하고 폴링으로 진행률을 제공했습니다. 사용자는 즉시 응답을 받고 진행률을 확인할 수 있게 되었습니다.

하지만 Grafana로 모니터링하던 중 엑셀 생성 작업의 CPU 사용률이 20-30%임을 확인했습니다. 이는 피드백이 30개 쌓인 단체의 경우였고, 임의로 500개를 삽입한 뒤 다운로드 요청을 모니터링한 결과 CPU 사용률은 100%까지 상승했습니다.
파일 생성은 CPU 집약적인 작업이었고 이를 API 서버에서 처리하는 것은 적절하지 않다고 생각했습니다. 다른 API 요청들의 응답 시간에도 영향을 줄 수 있는 위험 요소가 될 수 있기 때문입니다.
따라서 별도 서버로 분리를 고려했습니다.
문제 상황: API 서버 리소스 압박
기존 파일 생성 과정은 다음과 같았습니다. 비동기 작업으로 분리되어 있지만 여전히 같은 서버에서 실행됩니다.

다음과 같은 문제를 생각했습니다.
1. API 서버 리소스 압박
요청 스레드(톰켓 스레드 풀)를 사용하지 않고 비동기 스레드를 사용한다고 해서, 다른 API 요청 처리와 완전히 무관하다고 볼 수 없습니다.
둘 모두 같은 하드웨어 자원(CPU, 메모리 등)을 공유하기 때문입니다.
따라서 파일 생성 작업이 실행되어 CPU 사용률 증가하면 다른 API 요청 처리 성능, 응답 지연에 영향을 줄 수 있습니다.
2. 동시 요청 처리 제한
Spring의 @Async는 기본적으로 SimpleAsyncTaskExecutor를 사용하거나, 설정한 스레드 풀을 사용합니다. 만약 설정한 풀의 크기가 5개인데 파일 생성 요청 10개가 동시에 들어온다면 어떻게 될까요?
나머지 5개 요청은 파일 생성이 완료될 때까지 기다린 후에야 작업을 시작할 수 있어 응답 시간이 배로 증가합니다.
이를 해결하기 위해 풀의 크기를 늘리는 방법이 있지만, 근본적인 해결책은 아니라고 생각했습니다.
3. 확장성 부족
위와 같은 문제를 해결하기 위해 API 서버를 증설할 수 있습니다. 하지만 API 서버는 현재 다른 모든 API 요청도 처리하고 있는 상황이며 파일 생성 작업 하나 때문에 서버를 증설하는 것은 비효율적입니다. 별도로 스케일아웃 할 수 있어야 한다고 생각했습니다.
해결 방법: 작업 서버 분리
파일 생성 작업 서버를 분리하기 위해 여러 선택지를 고려했습니다.
먼저 API 서버를 스케일아웃하는 것이 아닌 파일 생성만을 담당하는 서버(EC2)를 분리하는 방법이 있었지만 비용 측면에서 적합하지 않았습니다.
파일 생성 요청은 현재 하루에 몇 번 정도로 빈도가 낮습니다. 하루 24시간 중 실제로 엑셀을 생성하는 시간은 1시간도 되지 않습니다. 파일 생성 작업을 수행하는 EC2를 따로 만든다면 나머지 23시간 동안 서버는 대기 상태로 있지만 비용은 계속 발생합니다.
이러한 문제를 해결하기 위한 대안으로 Lambda를 선택했습니다.
Lambda란?
Lambda는 AWS의 서버리스 컴퓨팅 서비스입니다. 서버를 직접 관리하지 않고 코드만 배포하면 요청이 들어올 때마다 AWS가 자동으로 실행 환경을 생성하고 코드를 실행합니다.
가장 큰 특징은 "이벤트 기반 실행"입니다. 특정 이벤트(SQS에 메시지 도착, S3 파일 업로드, HTTP 요청 등)가 발생했을 때만 함수가 실행되고 실행이 끝나면 환경이 자동으로 종료됩니다.
현재 엑셀 파일 생성은 특정 작업을 간헐적으로 수행하는 것이기 때문에 비용이나 스케일 아웃 등 여러가지 측면에서 Lambda가 적합하다고 생각했습니다.
1. 비용 절감
EC2는 앞서 말씀드린 것처럼 파일 다운로드 요청이 없어도 계속 실행되어 과금이 일어납니다. 반면 Lambda는 다운로드 요청을 받은 경우에만 실행되고 비용이 발생합니다. 프리티어 이용 시에는 100만번의 요청까지 무료로 제공하기도 합니다.
2. 자동 스케일링
동시 요청이 갑자기 늘어나도 Lambda는 자동으로 확장됩니다. 별도 설정 없이 즉시 스케일 아웃되며 요청이 줄어들면 자동으로 축소됩니다.
현재 구조에서 Lambda를 추가하게 되면 기존 비동기 스레드가 수행하던 일을 Lambda가 수행하는 구조가 되고, 파일 생성을 처리하는 컴퓨팅 자원이 분리됩니다.

Lambda 비동기 호출하기
API 서버에서 Lambda를 비동기로 호출하면 응답이 즉시 반환되고 Lambda가 백그라운드에서 작업을 처리하게 됩니다.
메시지 큐를 거치지 않는 이유
서버 간 통신에서 큐를 두는 이유는 연동 서버의 상태, 속도, 장애로부터 분리해 시스템의 안정성과 확장성을 확보하기 위함이라고 생각합니다.
다만 모든 비동기 작업에 큐가 항상 필요한 것은 아니고 작업의 성격에 따라 오히려 불필요한 복잡도가 될 수 있다고 판단했습니다.
예를 들어 많은 사례에서 SQS + Lambda 조합을 사용하는 것으로 알고 있습니다. 이메일 발송 시스템이라면 수천 명에게 동시에 메일을 보낼 때 SQS가 요청을 버퍼링하고 Lambda가 순차적으로 처리할 수 있습니다.
하지만 현재 프로젝트에서는 파일 생성 작업 요청이 SQS를 거칠 필요가 없다고 생각했습니다. 파일 생성 작업은 관리자만 사용 가능한 API이며 하루 10-30번 정도로 호출되는 횟수가 적고 작업 시간이 길다는 특성이 있습니다.
따라서 다음과 같은 이유로 API 서버에서 직접 Lambda로 통신하기로 결정했습니다.
1. 버퍼링이 불필요
메시지 큐의 주요 역할 중 하나는 트래픽 급증 시 요청을 버퍼링하는 것입니다. 예를 들어 이메일 발송 시스템에서 갑자기 1만 건의 요청이 들어오면, SQS가 큐에 쌓아두고 Lambda가 처리 가능한 속도로 처리합니다.
하지만 파일 다운로드 요청은 하루 30번 정도만 호출되며 동시 요청이 급증하는 패턴이 아니었습니다.
또한 Lambda는 현재 상황에서 충분히 높은 동시 실행 한도를 제공하므로 별도의 큐를 두지 않아도 Throttling 위험이 전혀 없습니다. 따라서 메시징 시스템 없이 바로 Lambda를 호출해도 충분하다고 생각했습니다.
2. 순서 보장이 불필요
SQS FIFO 큐는 메시지 처리 순서를 보장합니다. 하지만 엑셀 생성은 각 요청이 완전히 독립적입니다. 동시 요청이 올 때 A 단체의 파일이 먼저 생성되든, B 단체의 파일이 먼저 생성되든 상관없습니다. 순서를 보장할 필요가 없었습니다.
3. 복잡도 증가
중요한 것은 작업 상태를 일관되게 추적하고 사용자에게 진행률을 제공하는 것입니다. 이미 Job 테이블 기반으로 파일 생성/진행률/완료/실패 상태를 관리하고 있었기 때문에, SQS를 추가하면 "큐에 발행만 된 상태"와 같이 상태가 이원화되고 같은 메시징 운영 요소까지 포함해 설계 범위가 불필요하게 커진다고 생각했습니다.
따라서 단순한 구조인 API 서버에서 Lambda를 직접 호출하고, 상태는 DB에서 단일로 관리하는 방식을 선택했습니다.
Lambda 비동기 호출의 안정성 확보
또한 SQS 없이도 Lambda 비동기 호출은 다음 기능을 제공합니다.
- 자동 재시도 2회 (총 3회 시도)
- 실패에 대한 이벤트 설정 가능 (실패 시 DLQ 전송 등)
결과적으로 메시지가 SQS를 거치지 않아도 안전성을 충분히 확보할 수 있었습니다.
구현
이제 각 단계의 구현을 살펴보겠습니다.
EC2: Lambda 비동기 호출
파일 다운로드 작업 생성 서비스
public String createDownloadJob(final UUID organizationUuid) {
final var organization = organizationRepository.findByUuid(organizationUuid)
.orElseThrow(() -> new ResourceNotFoundException("해당 ID(id = " + organizationUuid + ")인 단체를 찾을 수 없습니다."));
// 작업 생성 & 저장
final FeedbackDownloadJob job = FeedbackDownloadJob.create(organizationUuid.toString());
feedbackDownloadJobDynamoDBRepository.save(job);
final List<Feedback> feedbacks = feedBackRepository.findByOrganization(organization);
final List<FeedbackData> feedbackDataList = feedbacks.stream()
.map(this::convertToFeedbackData)
.toList();
// 람다 페이로드 생성
final FeedbackExcelLambdaRequest lambdaRequest = new FeedbackExcelLambdaRequest(
job.getJobId(),
organizationUuid.toString(),
feedbackDataList
);
// 람다 호출
feedbackExcelLambdaService.invokeFeedbackExcelGeneration(lambdaRequest);
return job.getJobId();
}기존 비동기 스레드 호출 대신 Lambda를 호출합니다.
LambdaClient를 이용한 호출부
@Slf4j
@Service
@RequiredArgsConstructor
public class FeedbackExcelLambdaService {
private final LambdaClient lambdaClient;
private final LambdaProperties lambdaProperties;
private final ObjectMapper objectMapper;
public void invokeFeedbackExcelGeneration(final FeedbackExcelLambdaRequest request) {
try {
final String payload = objectMapper.writeValueAsString(request);
final InvokeRequest invokeRequest = InvokeRequest.builder()
.functionName(lambdaProperties.feedbackExcelFunctionName())
.invocationType(InvocationType.EVENT) // 비동기 호출
.payload(SdkBytes.fromUtf8String(payload))
.build();
lambdaClient.invoke(invokeRequest);
log.info("람다 호출 성공 jobId: {}", request.jobId());
} catch (JsonProcessingException e) {
throw new RuntimeException("Lambda 요청 직렬화 실패", e);
} catch (Exception e) {
throw new RuntimeException("Lambda 호출 실패", e);
}
}
}
Lambda 함수 구현
Lambda는 이미지 다운로드부터 S3 업로드까지 전체 파일 생성 과정을 처리합니다. 람다 함수 코드는 아래와 같이 aws 콘솔에서도 vs code로 작성할 수 있게 되어있습니다.

lambda_handler 함수
import json
import os
import tempfile
from datetime import datetime
import boto3
from openpyxl import Workbook
from openpyxl.drawing.image import Image as XLImage
from openpyxl.drawing.spreadsheet_drawing import TwoCellAnchor, AnchorMarker
from openpyxl.styles import Font, Alignment, PatternFill
from io import BytesIO
import requests
from PIL import Image
# AWS 클라이언트 초기화
s3_client = boto3.client('s3')
dynamodb = boto3.resource('dynamodb')
def lambda_handler(event, context):
try:
# 입력 파라미터 파싱
job_id = event['jobId']
organization_uuid = event['organizationUuid']
feedbacks = event.get('feedbacks', [])
print(f"Starting file generation for job: {job_id}, feedbacks count: {len(feedbacks)}")
# Job 상태를 PROCESSING으로 업데이트
update_job_status(job_id, 'PROCESSING', 0)
# 엑셀 파일 생성
excel_file = create_excel_file(feedbacks, job_id)
# S3 업로드
s3_url = upload_to_s3(excel_file, job_id)
# Job 상태를 COMPLETED로 업데이트
update_job_status(job_id, 'COMPLETED', 100, s3_url)
print(f"File generation completed: {s3_url}")
return {
'statusCode': 200,
'body': json.dumps({
'jobId': job_id,
'status': 'COMPLETED',
's3Url': s3_url
})
}
except Exception as e:
print(f"Error occurred: {str(e)}")
# 에러 발생 시 Job 상태 업데이트
if 'job_id' in locals():
update_job_status(job_id, 'FAILED', 0, error_message=str(e))
return {
'statusCode': 500,
'body': json.dumps({
'error': str(e)
})
}
흐름은 다음과 같습니다.
1. event 파싱
2. Job 상태를 PROCESSING으로 업데이트 (DynamoDB 호출)
3. 엑셀 파일 생성
4. S3 업로드
5. Job 상태를 COMPLETED로 업데이트
장애 대응: DLQ 모니터링
Lambda가 3회 재시도 후에도 실패하면 DLQ로 메시지가 전송됩니다. 하지만 DLQ에 메시지가 쌓여있다는 것만으로는 의미가 없습니다. 실패를 감지하고 대응할 수 있어야 합니다.
따라서 DLQ 모니터링과 알림 시스템을 구축했습니다. 전체 흐름은 아래와 같습니다.

1. Lambda에 DLQ 연결
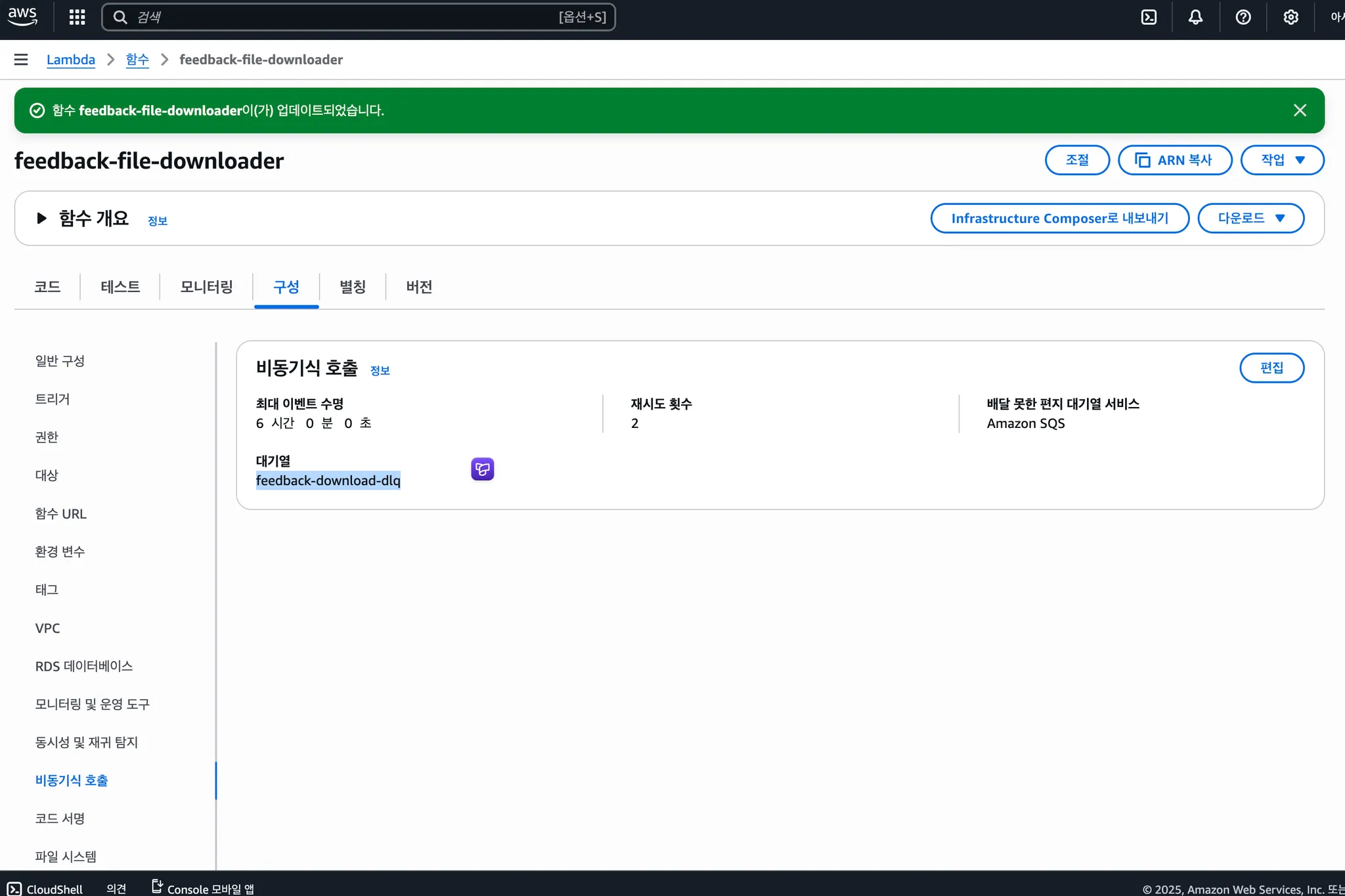
먼저 Lambda 함수에 DLQ를 연결합니다. 비동기 호출 구성에서 실패한 이벤트가 전송될 대상을 지정합니다.
- DQL: Amazon SQS
- 대기열: feedback-download-dlq
- 재시도 횟수: 2회 (총 3회 시도)
2. DLQ 동작 확인
DLQ가 제대로 작동하는지 확인하기 위해 의도적으로 Lambda에서 에러를 발생시켰습니다.


Lambda를 실행하면 2회 재시도가 실패하면 DLQ로 메시지가 전송됩니다.
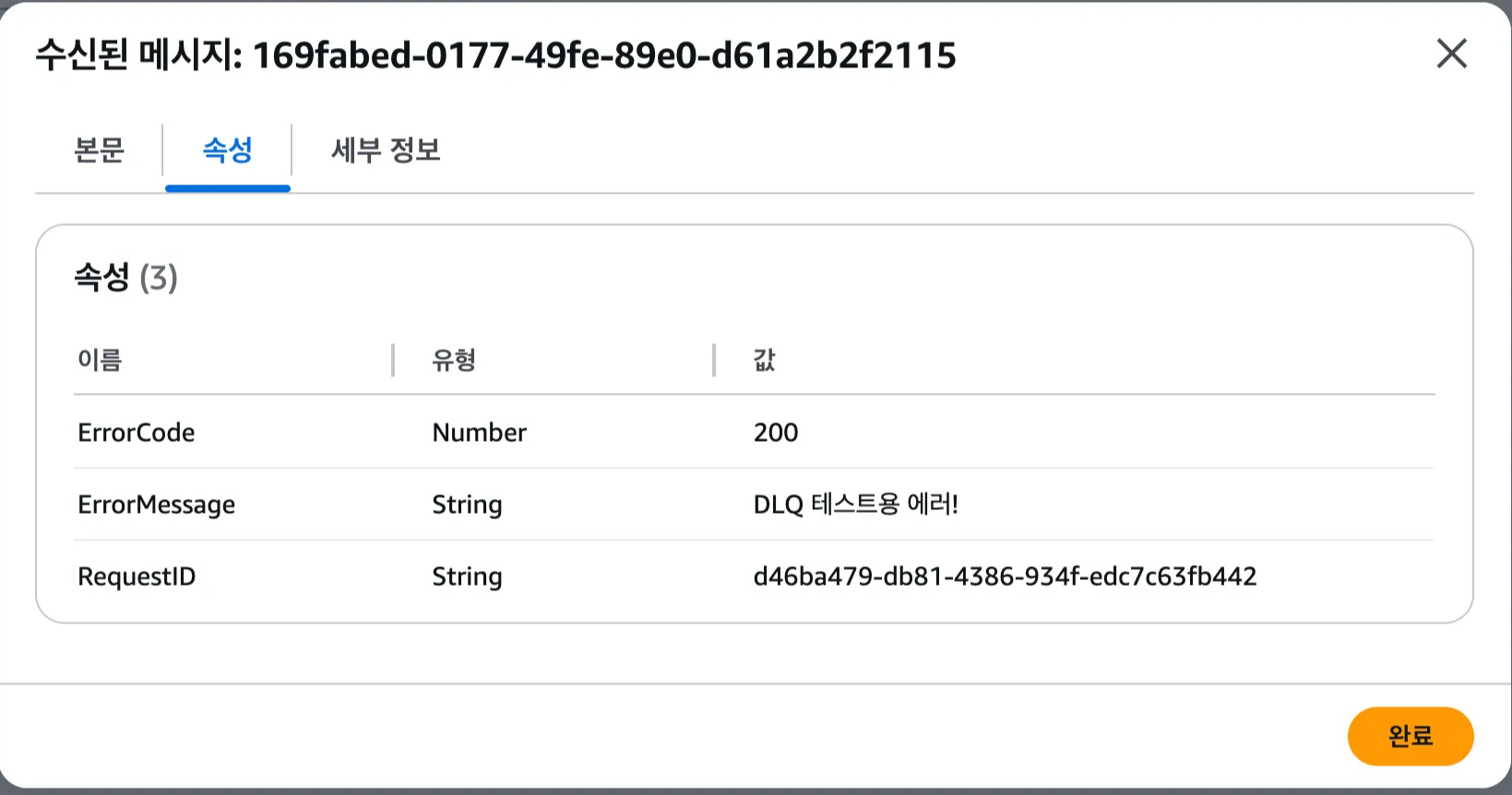
DLQ에서 메시지를 확인하면 위처럼 정보가 포함되어 있습니다. 본문도 확인할 수 있습니다.
3. CloudWatch 경보 생성
DLQ에 메시지가 들어오면 즉시 감지할 수 있도록 CloudWatch 경보를 설정합니다.

4. SNS로 경보 알림 전달 & Lambda 트리거
경보가 발생하면 SNS 토픽으로 알림을 전달하고, SNS가 Discord 알림 Lambda를 트리거합니다.
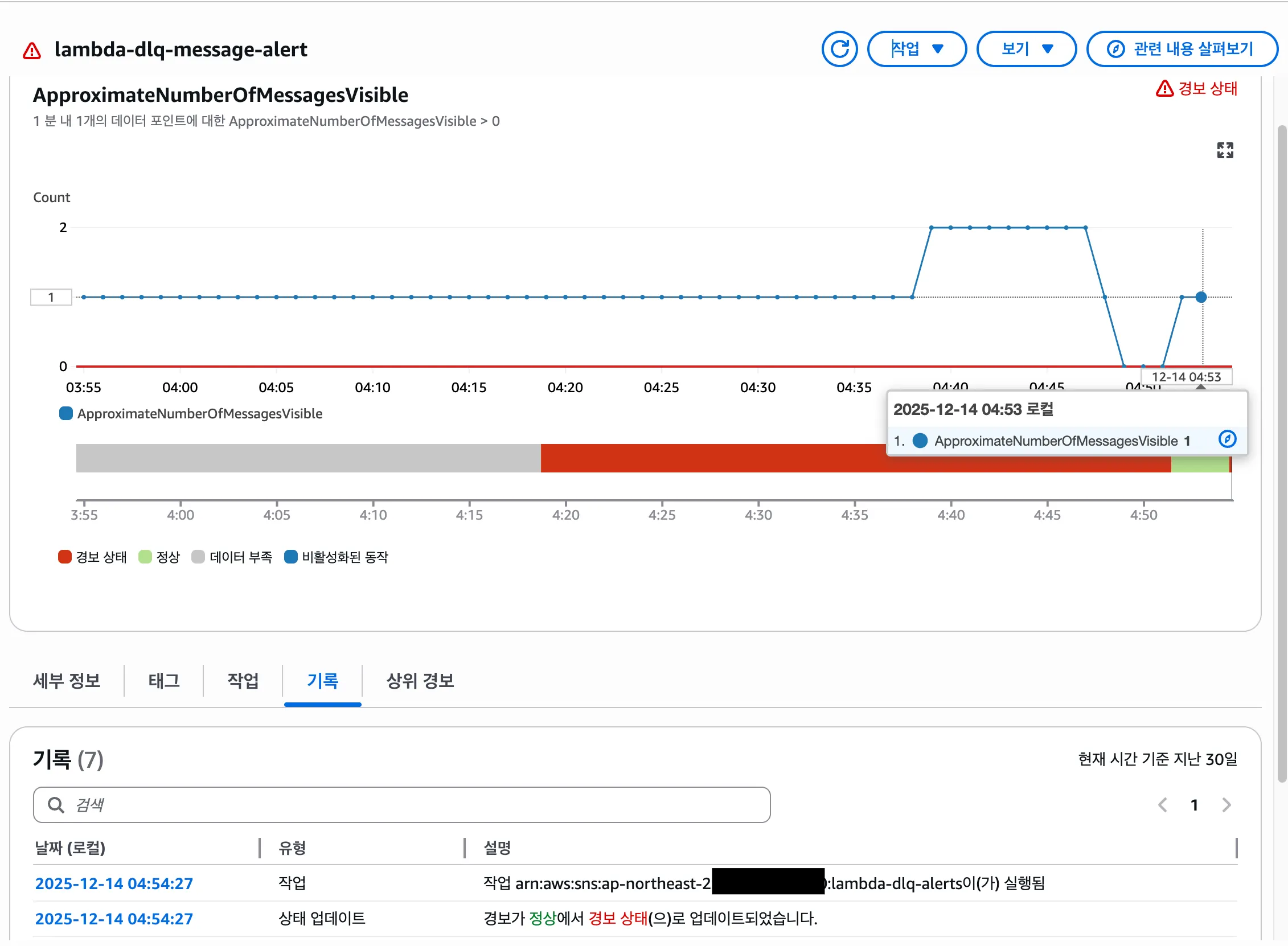
경보 그래프를 보면
- 4:00경 DLQ에 메시지가 쌓이면서 Count가 1로 증가
- 즉시 경보 상태(빨간색)로 전환
- SNS로 알림 발송
이 됩니다.
5. Discord 웹훅 알림 Lambda 실행
SNS가 트리거되면 Discord 알림을 보내는 Lambda 함수가 실행됩니다.

결과
Lambda로 분리한 후 변화는 다음과 같습니다.
성능 개선
API 서버 CPU 사용률은 파일 생성 시 20-30%, 피드백 수가 많으면 100%까지도 점유했습니다. 하지만 파일 생성 작업이 Lambda로 완전히 분리되면서 API 서버의 CPU 사용률 변화에 끼치는 영향이 사라졌습니다.
비용 분석
Lambda 비용
하루 평균 30건의 파일 생성 요청이 발생한다고 가정하면 한 달 기준 약 900건입니다.
- 실행 시간: 평균 1분 × 900건 = 900분
- 메모리: 256MB
- 비용: $0 (프리티어 범위 내)
프리티어가 끝나더라도 월 $0.20 미만으로 매우 저렴합니다.
DLQ(SQS) 비용
- 월 실패 건수: 10건 미만 (정상 운영 시)
- SQS 프리티어: 월 100만 요청 무료
- 비용: $0 (프리티어 범위 내)
Lambda vs EC2 t4g.small 비교
만약 EC2를 별도로 증설했다면
- EC2 t4g.small (2 vCPU, 2GB RAM): 월 $12
- 24시간 가동되지만 실제 사용은 1시간 미만
- 유휴 시간 비율: 약 95%
Lambda 선택으로 월 $12 → $0, 비용을 완전히 제거할 수 있었습니다.
안전성 확보
Lambda 전환으로 비용뿐만 아니라 안정성도 개선되었습니다. 일시적인 네트워크 오류나 외부 API 장애가 발생해도 Lambda가 자동으로 2회 재시도합니다. 2회 재시도 후에도 실패하면 DLQ에 메시지가 저장됩니다.
DLQ에 메시지가 들어오면 Discord로 즉시 알림을 받습니다. 장애를 빠르게 인지하고 대응할 수 있습니다.
또한 파일 생성 작업이 실패해도 API 서버에는 영향을 주지 않습니다. 사용자는 여전히 다른 기능을 정상적으로 사용할 수 있습니다.
마무리
처음에는 "서버 간 통신이라면 메시지 큐를 써야 하나?" 고민했습니다. 하지만 작업의 특성에 따라 Lambda 직접 호출만으로도 충분했습니다. 또한 Lambda 자체의 내장 기능(비동기 호출, 자동 재시도)만으로도 충분한 운영 안전성을 확보할 수 있었습니다.
이어서 DLQ와 CloudWatch 알람으로 실패한 작업을 놓치지 않을 수 있었습니다. 장애를 빠르게 감지하고 대응할 수 있는 시스템을 갖추는 것이 중요하다는 것을 다시 한번 느꼈습니다.
이번 경험을 통해 서버리스 아키텍처의 장점을 직접 체감할 수 있었고, 비용 절감과 안정성을 동시에 얻을 수 있다는 것을 배웠습니다!
읽어주셔서 감사합니다.
참고자료
https://docs.aws.amazon.com/lambda/latest/dg/invocation-async.html
https://docs.aws.amazon.com/AmazonCloudWatch/latest/monitoring/AlarmThatSendsEmail.html