
배경
이전 글에서 BlockingQueue 기반 이미지 다운로드 병렬 처리를 통해 성능을 개선했습니다. 이미지가 포함된 피드백 50개 (운영 서버 내 단체의 피드백 평균 개수) 기준으로 다운로드 시간을 5초에서 500ms로 단축하였고, 메모리 사용량도 안정적으로 제어할 수 있었습니다.
하지만 파일 생성 과정 전체로 보면 여전히 긴 시간이 소요됐습니다. 이미지 다운로드 외에도 피드백 조회, 엑셀 생성과 이미지 삽입, 디스크 flush 등 여러 단계를 거쳐야 했기에 결과적으로 전체 파일 생성에는 약 10초가 소요되었습니다.
여기서 문제는 이 10초 동안 사용자에게 아무런 응답을 주지 못한다는 것이었습니다. 사용자는 다운로드 버튼을 누른 후 서버에서 파일 생성이 완료되는 10초 간 응답을 받지 못하고, 파일이 완성된 후 스트리밍 응답을 받기 시작하여 브라우저에서 다운로드가 시작되었습니다.
초기 구현: 동기 처리 방식
처음 구현은 사용자가 다운로드 버튼을 클릭하면 요청 스레드에서 파일을 생성하고 완성된 후 사용자에게 스트리밍 응답하는 방식이었습니다.

@Override
public void downloadFeedbacks(
final LoginOrganizerInfo loginOrganizerInfo,
final UUID organizationUuid,
final HttpServletResponse response
) {
response.setContentType("application/vnd.openxmlformats-officedocument.spreadsheetml.sheet");
final ContentDisposition contentDisposition = ContentDisposition.attachment()
.filename(fileName, StandardCharsets.UTF_8)
.build();
response.setHeader(HttpHeaders.CONTENT_DISPOSITION, contentDisposition.toString());
adminFeedbackService.downloadFeedbacks(
loginOrganizerInfo.organizationUuid(),
response.getOutputStream()
);
}
동기 처리를 선택한 이유는 단순한 구현 때문이었습니다. API 하나로 파일 생성부터 다운로드까지 하나의 HTTP 요청-응답으로 완료된다는 장점이 있었습니다.
문제1: 사용자에게 장시간 응답 부재
그러나 파일 생성 작업을 요청 스레드에서 동기적으로 처리하고 작업 완료 후에 응답을 반환하는 구조는 사용자 경험이 좋지 않았습니다.
예를 들어 파일 생성부터 완료까지 30초가 소요된다고 하면 사용자는 30초 간 아무런 응답을 받지 못합니다. 그 이유는 HttpServletResponse의 outputStream에 파일 쓰이기 시작하는 시점이 다운로드가 시작되는 시점이기 때문입니다.
왜 기다려야할까?
그래서 저는 처음 아래 그림과 같이 파일이 생성되는 대로 파일 조각을 outputStream에 바로 써주면 되지 않나? 라고 생각했습니다.
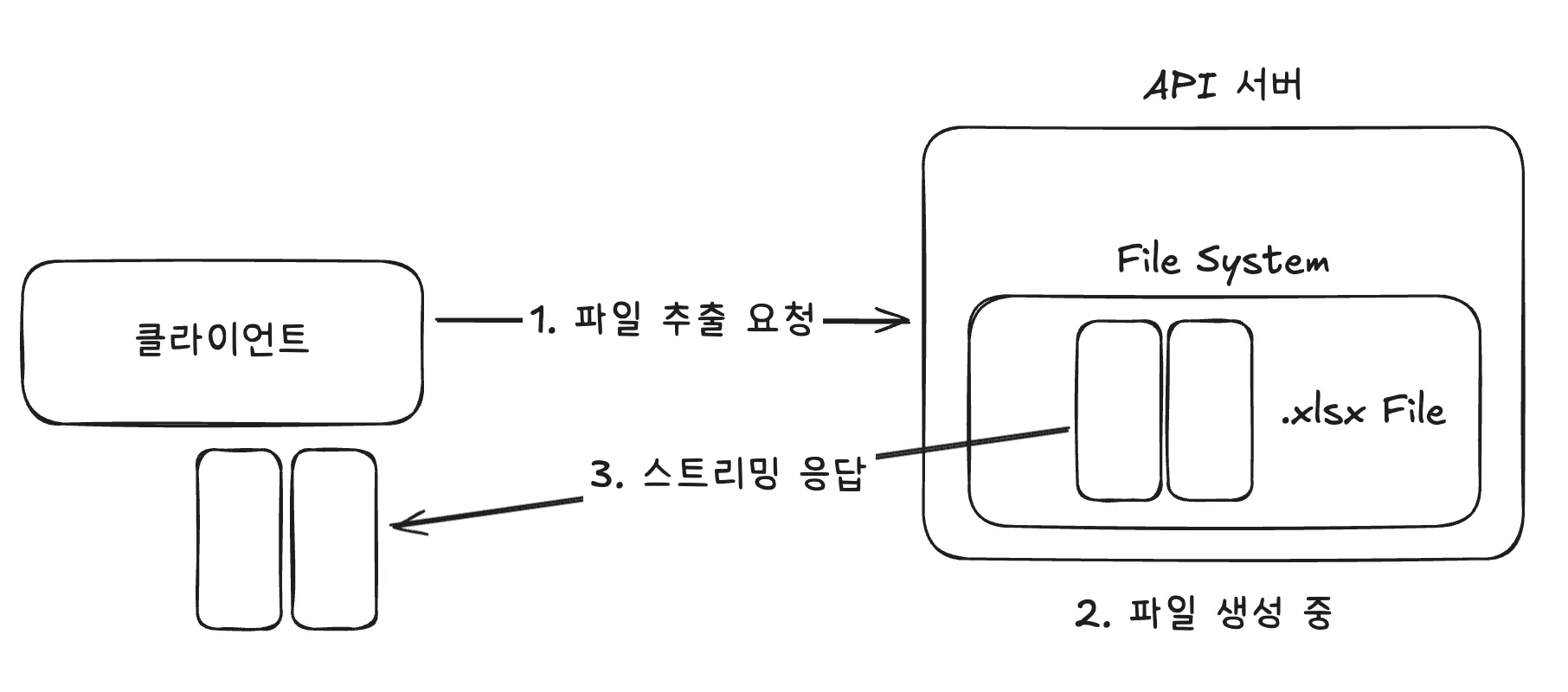
파일이 생성되는 족족 바로 클라이언트에게 보내주고, 클라이언트가 이를 조합해서 파일을 완성할 수 있다면 좋겠지만 이는 불가능했습니다.
SXSSFWorkbook의 write() 메서드는 모든 row를 다 만든 후에야 ZIP 패키징을 시작하고, 그제야 스트리밍으로 클라이언트에 전달하기 때문입니다.
workbook.write(outputStream);
.xlsx 파일은 ZIP으로 압축된 여러 XML 파일의 묶음이며 메타데이터, 시트 간 관계, 스타일 정보 등이 모두 정의되어야 유효한 엑셀 파일이 됩니다. 부분적으로 보낸 청크는 유효한 엑셀 파일이 아니므로 클라이언트에서 조합할 방법이 없습니다.
결국 "파일 완성 → ZIP 패키징 → 스트리밍 시작"이라는 과정을 거쳐야 하고, 사용자는 이 모든 과정이 끝날 때까지 기다려야 합니다.
즉 파일이 모두 완성되고 나서 이를 클라이언트에 쪼개서 응답하는 것입니다.

문제2: 타임아웃 위험
이외에도 타임아웃 문제가 있습니다.
현재 사용중인 nginx 서버에는 proxy read timeout이 30초로 설정되어 있습니다.
현재 파일 생성에 평균적으로 약 10초가 걸리지만, 이는 피드백 50개 기준입니다. 만약 피드백이 100개, 500개인 단체라면 이미지가 많고 용량이 커져 파일 생성 시간은 30초를 넘어갑니다.
30초가 넘어가면 nginx는 read timeout에 의해 애플리케이션 서버와의 연결을 끊고 클라이언트에게 504(gateway timeout)를 반환합니다.
더 큰 문제는 서버에선 파일 생성이 계속 진행 중이라는 점입니다. 요청 처리를 위한 스레드 풀의 스레드를 계속 점유하는 자원 낭비로 이어집니다.
이를 해결하기 위해 proxy read timeout 값을 늘릴 수도 있습니다. 하지만 이를 늘려 해결하더라도 첫 번째 문제였던 사용자에게 응답을 주지 못한다는 점은 해결되지 않습니다. 또한 설령 늘렸다고 하더라도 시간이 지나 피드백 개수가 늘어나면 그에 따라 타임아웃 시간을 늘려야하기 때문에 근본적인 해결책이 되지 못한다고 생각했습니다.
또한 파일 생성과 같은 장시간 작업을 스레드 풀에서 처리하게 되면 다른 API의 지연까지 영향을 끼칠 수 있습니다.
해결: 비동기 작업으로 전환
어떻게 하면 사용자가 아무 응답 없이 기다리지 않고 파일을 다운받을 수 있을지 고민했습니다. 근본적인 문제는 "파일이 완성될 때까지 응답할 수 없다"는 것이라 생각했습니다.
따라서 API를 분리하는 것을 생각했습니다. 첫 번째 요청에서는 "작업을 시작했음"을 빠르게 알려주고, 파일 생성은 백그라운드에서 진행하는 것입니다.
이후 사용자는 진행 상황을 조회하는 API를 호출하는 것입니다. "45%", "80%" 등의 값으로 보여주면 다운로드가 진행되고 있다는 확신을 가질 수 있고 대략 얼마나 더 기다려야 하는지도 예상할 수 있어 사용자 경험을 개선할 수 있습니다.
따라서 결과적으로 API를 3가지로 분리했습니다.
- 작업 생성 요청 (즉시 응답)
- 진행률 조회 (폴링)
- 파일 다운로드 (s3 download presigned url)
사용자는 다운로드 버튼을 누르면 즉시 작업 ID를 받습니다. 그리고 주기적으로 진행 상황을 확인하다가, 완료되면 파일을 다운로드합니다.

기능 흐름
API를 호출하는 전체 흐름을 단계별로 정리하면 다음과 같습니다.
1. 사용자가 다운로드 버튼 클릭
- 작업 생성 API 호출
- 서버는 파일 생성 비동기 처리 후 즉시 작업 ID 반환
2. 백그라운드에서 파일 생성 시작
- 비동기 스레드가 피드백 데이터 조회
- 엑셀 생성
- 완성된 파일을 S3에 업로드
3. 클라이언트가 진행 상황 확인
- 3초마다 진행률 조회 API 호출
- 작업 상태 확인 (PENDING → PROCESSING → COMPLETED)
- 작업 (0~100 값)% 확인
4. 완료 후 파일 다운로드
- 파일 다운로드 API 호출
- S3 Presigned URL로 리다이렉션
- 사용자가 파일 다운로드
구현
이제 각 단계의 구현을 살펴보겠습니다.
1. 작업 생성
@Override
public SuccessResponse<FeedbackDownloadJobResponse> createDownloadJob(
final LoginOrganizerInfo loginOrganizerInfo,
final UUID organizationUuid
) {
final String jobId = adminFeedbackService.createDownloadJob(organizationUuid);
return SuccessResponse.success(HttpStatus.ACCEPTED, new FeedbackDownloadJobResponse(jobId));
}서비스 레이어에서는 작업 객체를 생성하고 저장한 뒤, 비동기 메서드를 호출합니다.
public String createDownloadJob(final UUID organizationUuid) {
if (!organizationRepository.existsOrganizationByUuid(organizationUuid)) {
throw new ResourceNotFoundException("해당 ID(id = " + organizationUuid + ")인 단체를 찾을 수 없습니다.");
}
final FeedbackDownloadJob job = FeedbackDownloadJob.create(organizationUuid.toString());
feedbackDownloadJobStore.save(job);
feedbackFileDownloadService.createAndUploadFileAsync(job.getJobId(), organizationUuid);
return job.getJobId();
}이 메서드는 즉시 반환되므로 사용자는 바로 응답을 받습니다. 실제 파일 생성은 비동기 스레드에서 진행됩니다.
2. 비동기 파일 생성
@Service
@RequiredArgsConstructor
public class FeedbackFileDownloadService {
@Async
public void createAndUploadFileAsync(final String jobId, final UUID organizationUuid) {
final FeedbackDownloadJob job = feedbackDownloadJobStore.getById(jobId);
Path tempFile = null;
try {
// 1. 피드백 데이터 조회
final Organization organization = organizationRepository.findByUuid(organizationUuid)
.orElseThrow(() -> new ResourceNotFoundException("단체를 찾을 수 없습니다."));
final List<Feedback> feedbacks = feedBackRepository.findByOrganization(organization);
// 2. 임시 파일에 엑셀 생성
tempFile = Files.createTempFile("feedback-", ".xlsx");
try (FileOutputStream fileOutputStream = new FileOutputStream(tempFile.toFile())) {
feedbackExcelDownloader.download(organization, feedbacks, fileOutputStream, jobId);
}
// 3. S3 업로드
final String s3Url;
try (FileInputStream fileInputStream = new FileInputStream(tempFile.toFile())) {
s3Url = s3UploadService.uploadFile("xlsx", "feedback_file", jobId, fileInputStream, fileSize);
}
// 4. 작업 완료 처리
job.completeWithUrl(s3Url);
} catch (Exception e) {
log.error("파일 생성 중 오류 발생. jobId={}", jobId, e);
job.fail("파일 생성 중 오류가 발생했습니다: " + e.getMessage());
} finally {
// 5. 임시 파일 삭제
if (tempFile != null) {
Files.deleteIfExists(tempFile);
}
}
}
}@Async 어노테이션으로 별도 스레드에서 실행됩니다. 파일 생성이 완료되면 S3에 업로드하고 작업 상태를 COMPLETED로 업데이트합니다.
임시 파일을 사용하는 이유
엑셀 파일을 메모리에서 바로 S3로 업로드할 수도 있지만, 임시 파일을 거치는 이유는 메모리 안정성 때문입니다.
메모리 안정성을 위해 기존에 XSSFWorkbook이 아닌, 엑셀 파일을 디스크에 스트리밍하는 SXSSFWorkbook을 사용했습니다. 하지만 S3 업로드 시 엑셀 파일을 byte로 변환해서 전달하게 되면, byte로 변환되는 과정에서 전체 파일이 메모리에 올라가게 됩니다.
ByteArrayOutputStream byteArrayOutputStream = new ByteArrayOutputStream();
workbook.write(byteArrayOutputStream);
byte[] fileData = byteArrayOutputStream.toByteArray(); // 전체 파일이 메모리에 적재
s3Client.upload(fileData); // OOM 위험따라서 FileOutputStream으로 임시파일로 먼저 저장한 뒤 FileInputStream으로 읽어서 S3로 업로드하는 방식을 선택했습니다.
이렇게 하면 파일을 S3에 업로드하기까지 과정에서 메모리 사용량을 제어할 수 있습니다.
다음으로 비동기 파일 생성 중 사용자는 진행률을 조회할 수 있습니다.
3. 진행률 조회
@Override
public SuccessResponse<FeedbackDownloadJobStatusResponse> getDownloadJobStatus(
final LoginOrganizerInfo loginOrganizerInfo,
final UUID organizationUuid,
final String jobId
) {
final FeedbackDownloadJob job = adminFeedbackService.getDownloadJobStatus(jobId);
return SuccessResponse.success(HttpStatus.OK, FeedbackDownloadJobStatusResponse.from(job));
}작업 객체를 조회해서 반환합니다. 클라이언트는 이 API를 초마다 호출해서 status가 COMPLETED가 되기를 기다립니다.
4. 파일 다운로드
@Override
public void downloadFile(
final LoginOrganizerInfo loginOrganizerInfo,
final UUID organizationUuid,
final String jobId,
final HttpServletResponse response
) {
final String downloadUrl = adminFeedbackService.getDownloadUrl(jobId);
response.setStatus(HttpServletResponse.SC_FOUND);
response.setHeader(HttpHeaders.LOCATION, downloadUrl);
}
작업이 완료되면 S3 Presigned URL을 반환합니다. 클라이언트는 이 URL로 리다이렉션되어 파일을 다운로드합니다.
개선효과

사용자는 버튼을 클릭하면 즉시 응답을 받고 "작업이 시작되었습니다"라는 메시지와 함께 프로그레스 바가 표시됩니다.
이후 진행률을 조회하여 사용자는 "45%, 80% 완료" 와 같은 정보를 보고 사용자 경험이 나아질 수 있었습니다.
마무리
비동기롤 처리하면서 작업 상태 관리, 에러 처리, 폴링 등 고려할 부분이 많아졌지만, 사용자에게 즉각적인 피드백을 줄 수 있었고 타임아웃 위험도 제거할 수 있었습니다.
평소에는 요청을 받아서 DB를 조회하거나 저장하고, 즉시 응답하는 방식의 단순한 JSON을 주고받는 API를 주로 만들었습니다. 하지만 장시간 작업이 될 수 있는 파일 생성 기능을 만들면서 새로운 고민을 하는 계기가 되었고, 배운 점이 많았던 것 같아 뿌듯합니다!
읽어주셔서 감사합니다.
'woowacourse > project' 카테고리의 다른 글
| Blue-Green 무중단 배포 파이프라인 구축하기 (0) | 2025.10.26 |
|---|---|
| 병렬 처리하면 무조건 좋을까? : BlockingQueue로 파일 다운로드 성능 & OOM 개선하기 (0) | 2025.10.07 |
| 실시간 로그 모니터링 시스템 구축하기 (Alloy, Loki, Grafana) (4) | 2025.08.03 |
| 로깅, 왜 해야할까? (1) | 2025.08.02 |