
배경
두게더 서비스의 핵심 기능 중 하나는 챌린지 그룹 멤버들 사이의 상호작용입니다. 사용자가 투두를 완료하면 사진과 설명으로 인증을 요청하고, 같은 그룹의 다른 멤버가 그것을 검사해서 인정하거나 거절하는 방식입니다.

즉, 사용자는 투두 작성 → 인증 생성 → 알림 → 검사 이라는 흐름을 거치게 됩니다.
알림을 통해 사용자들은 상호작용하며 챌린지를 이어가며, 인증 → 알림은 서비스에서 정말 중요한 기능이라고 할 수 있습니다.
현재 코드
투두 인증 요청을 하게 되면 현재 다음과 같은 순서로 동작합니다.
@Transactional
public void certifyDailyTodo(
final Long memberId,
final Long dailyTodoId,
final String certifyContent,
final String certifyMediaUrl
) {
// 1. 투두 인증 정보 저장 (DB Insert)
final DailyTodoCertification dailyTodoCertification = createDailyTodoCertification(
dailyTodo, writer, certifyContent, certifyMediaUrl, dailyTodoStats);
// 2. 검사자 선정 (DB Insert)
final Optional<Member> reviewer = pickDailyTodoCertificationReviewer(
challengeGroup, writer, dailyTodoCertification);
// 3. FCM 알림 전송
reviewer.ifPresent(target -> sendNotificationToReviewer(target, writer, dailyTodo));
}투두 인증 정보 저장부터 FCM 알림 발송까지 모든 과정이 하나의 트랜잭션 내에서 일어납니다. 응답은 FCM 호출이 완료될 때까지 기다렸다가 반환됩니다.
문제 상황: DB 트랜잭션 내에서 호출하는 외부 API (FCM)
앞서 본 코드에서 문제로 인식한 부분은 다음과 같습니다. 외부 API인 FCM의 호출이 DB 트랜잭션 내부에 있다는 것입니다.
이것은 우리가 직접 제어할 수 없는 외부 서비스의 성능에 우리 시스템의 응답 속도가 의존하게 된다는 뜻입니다. DB 커넥션이라는 한정된 자원을 장시간 점유하게 되면서 다른 API 요청들까지 영향을 받을 수 있습니다.
DB 커넥션 점유 상황
위의 투두 인증 서비스 코드를 다시 보겠습니다.
@Transactional
public void certifyDailyTodo() {
// 투두 인증 정보 저장 (DB Insert)
// 검사자 선정 (DB Insert)
// FCM 알림 전송 -> 응답까지 대기 -> DB 커넥션 점유
reviewer.ifPresent(target -> sendNotificationToReviewer(target, writer, dailyTodo));
}sendNotification()은 현재 동기 블로킹 방식으로 호출하고 있습니다. 이 메서드가 FCM 서버로 요청을 보내고, 응답을 받을 때까지 다음 줄로 진행하지 않습니다.
문제는 이 동안 DB 커넥션이 그대로 점유된다는 것입니다. 투두 인증 정보는 이미 저장됐고, 트랜잭션은 여전히 활성 상태입니다. 커넥션은 반환되지 않은 채로 FCM 응답을 기다리게 됩니다.
알림 전송 요청 후 응답이 오기까지 500ms가 걸린다면, 이 DB 커넥션은 DB 작업이 끝났음에도 500ms 동안 추가로 점유됩니다. 600ms 걸린다면 600ms 점유되겠죠. 즉, 외부 API의 응답 시간만큼 커넥션이 묶여있게 됩니다.
DB 커넥션 고갈이 초래하는 연쇄 효과
현재 저희 프로젝트에서는 커넥션 풀 라이브러리로 HikariCP를 사용하고 있고 풀 크기 기본값인 10개를 그대로 이용하고 있습니다. 즉, 동시에 최대 10개의 DB 커넥션만 유지할 수 있습니다.
이때 투두 인증 요청이 동시에 10개 들어온다면 어떻게 될까요? 10개 요청 스레드 모두 FCM 호출에서 멈추게 되고, 그에 따라 10개의 DB 커넥션이 모두 점유됩니다.

이 순간에 다른 사용자가 "투두 목록 조회"를 요청했다고 가정해보겠습니다. 이 요청은 DB 커넥션을 얻기 위해 FCM 응답 시간(ex. 500ms)만큼 더 대기해야 합니다. 단순한 SELECT 쿼리임에도 불구하고 DB 커넥션을 얻기 위해 아무 관계 없는 외부 API 응답을 기다리는 상황입니다.

만약 10개의 요청보다 훨씬 더 많은 요청이 동시에 들어온다면 어떻게 될까요? 커넥션 풀을 기다리는 대기 큐가 길어지고, 더 많은 요청 처리 스레드가 커넥션을 얻기 위해 대기하게 됩니다.
Tomcat의 스레드 풀(기본값 200개)이 빠르게 소진되기 시작하고 결국 스레드 풀까지 고갈되면, 새로운 요청은 들어오자마자 처리할 스레드가 없어 작업 큐에 쌓이게 됩니다.

작업 큐에 요청들이 쌓인다는 것은 그만큼 활성 연결들도 증가하고 있다는 뜻입니다. 활성 연결 수가 max-connections에 도달하게 되면 연결 수립을 대기하는 요청들이 os backlog queue에 쌓이고, 그 크기가 초과되면 이후 연결 시도는 거부됩니다.

위 예시에서 FCM 응답 시간을 500ms로 가정했지만, 사실 외부 서버의 응답 시간은 우리가 예측할 수 없고, 통제할 수도 없습니다.
만약 FCM 서버가 일시적인 지연을 겪는다면 요청당 3초, 5초 그 이상이 걸릴 수도 있습니다. 그러면 DB 커넥션은 그만큼 더 오래 점유되고 장애 전파의 정도는 더욱 심해집니다.
이것이 외부 API를 트랜잭션 내부에서 호출하는 것이 위험한 이유라고 생각합니다. 제어할 수 없는 외부 요인에 의해 우리 서비스의 안정성이 좌우됩니다.
해결: 외부 API를 트랜잭션 밖으로 분리
외부 API 호출을 트랜잭션 밖으로 꺼내는 방법은 여러 가지가 있습니다.
대안1: ApplicationService 추가
@Service
public class CertificationApplicationService {
public void certifyDailyTodo(Long memberId, Long dailyTodoId, String content) {
// 트랜잭션 범위 내: DB 작업만
certificationService.certify(memberId, dailyTodoId, content);
// 트랜잭션 범위 외: 외부 API 호출
notificationService.sendNotification(...);
}
}
DB 작업을 수행하는 서비스와 외부 API를 호출하는 서비스를 오케스트레이션하는 애플리케이션 서비스를 추가할 수 있습니다. DB 커밋 후 커넥션을 반환한 뒤 외부 API 호출이 이뤄지기 때문에 외부 API 호출 시간동안 DB 커넥션을 점유하지 않습니다.
대안2: 비동기 스레드
@Transactional
public void certifyDailyTodo() {
// 1. 투두 인증 정보 저장 (DB Insert)
final DailyTodoCertification dailyTodoCertification = createDailyTodoCertification(dailyTodo, writer, certifyContent, certifyMediaUrl, dailyTodoStats);
// 2. 검사자 선정 (DB Insert)
final Optional<Member> reviewer = pickDailyTodoCertificationReviewer(challengeGroup, writer, dailyTodoCertification);
// 3. FCM 알림 전송
reviewer.ifPresent(target -> sendNotificationToReviewer(target, writer, dailyTodo));
}
@Service
public class NotificationService {
@Async
public void sendNotification(Long reviewerId, String title, String message) {
fcmClient.send(reviewerId, title, message);
}
}sendNotification() 메서드에 @Async 어노테이션을 붙여 별도의 스레드에서 비동기로 실행할 수 있습니다. 트랜잭션이 커밋되고 메인 스레드는 반환되며, FCM 호출은 별도의 스레드에서 처리됩니다.
두 가지 방법이 모두 가능하지만 저는 비동기 처리를 선택했습니다.
선택한 이유는 다음과 같습니다.
1. 빠른 응답 속도
비동기 스레드로 알림 발송을 처리한다면 인증 요청에 대해서 DB 저장 후 바로 사용자에게 응답을 할 수 있기 때문에 API의 응답 시간이 감소합니다. 사실 투두 인증 자체는 인증 정보를 DB에 저장하는 순간 완료됩니다. 알림 발송은 인증의 마지막 과정이며 인증 요청을 한 사용자가 알림 발송까지 기다리지 않아도 된다고 생각했습니다.
2. 알림 발송이 즉시 이뤄질 필요가 없다
사용자가 투두를 인증하는 순간 즉시 검사자에게 알림이 가지 않아도 됩니다. 물론 몇십 분, 몇 시간 뒤라면 검사가 늦어져 사용자 경험에 영향이 가겠지만, 몇십 초 정도라면 문제가 없습니다. 검사자는 실제 인증 시점과 알림이 온 시점의 차이를 인지하지 못하기 때문입니다.
새로운 문제: 알림 발송 신뢰성 보장
트랜잭션 내부에서 호출
기존에는 알림 발송을 할 때까지 모든 과정이 하나의 트랜잭션 내에 있었습니다.

두 작업에 대해 원자성이 보장되어 인증만 저장되고 알림이 실패하는 경우는 발생하지 않습니다. 인증이 저장된 후 알림 발송이 실패하면, 트랜잭션이 롤백되어 인증도 함께 실패하기 때문입니다.
case 1 (o o): 인증 저장 성공, 알림 발송 성공 -> 성공 응답
case 2 (o x): 인증 저장 성공, 알림 발송 실패 -> tx 롤백 후 에러 응답 (알림 발송 실패에 대해 catch해서 에러 로그만 남기고 성공 응답을 보낼 수도 있습니다.)
case 3 (x o): 인증 저장 실패, 알림 발송 성공 -> 발생 불가 케이스
case 4 (x x): 인증 저장 실패, 빠른 실패로 알림 발송 요청X -> 에러 응답
이 경우에는 인증은 되었지만, 알림 발송이 진행되지 않은 상태가 존재할 수 없습니다.
하지만 FCM 서버 장애로 인해 알림 발송이 불가능한 상황이라면 이에 영향을 받아 인증 저장도 불가능하게 됩니다.
트랜잭션 밖에서 호출
이번엔 트랜잭션으로부터 알림 발송을 비동기 스레드로 분리했을때 케이스를 알아보겠습니다.

트랜잭션 외부로 분리되었기 때문에 이제 인증은 저장되었지만 알림 발송이 실패하는 상황이 발생할 수 있습니다.
- 인증 저장: 트랜잭션 내 (이미 커밋됨)
- 알림 발송: 트랜잭션 밖 (별도 스레드)
case 1 (o o): 인증 저장 성공, 알림 발송 성공 -> 성공 응답
case 2 (o x): 인증 저장 성공, 알림 발송 실패 -> 성공 응답
case 3 (x o): 인증 저장 실패, 알림 발송 성공 -> 발생 불가 케이스
case 4 (x x): 인증 저장 실패, 빠른 실패로 알림 발송 요청X -> 에러 응답
사용자 입장에서 바라보면, 투두 인증 요청을 한 사용자는 인증을 하고 인증이 성공했음을 즉시 확인합니다. 성공 응답을 받았으니 "검사자가 알림을 받겠지?"라는 기대를 하게 됩니다.
하지만 실제로는 그 뒤 비동기 스레드에서 알림 발송이 진행되고 있고, 만약 이 과정에서 장애가 발생한다면 검사자는 알림을 받지 못합니다.
이러한 케이스가 비동기 처리로 인한 신뢰성 문제라고 생각합니다. 사용자의 기대와 실제 시스템의 동작이 불일치하게 됩니다.
알림 전송 신뢰성 보장하기
대안1. 단순 재시도
가장 단순한 해결책은 실패한 알림을 비동기 스레드 내에서 단순히 재시도하는 것입니다.
@Service
public class NotificationService {
@Async
@Retryable(
maxAttempts = 3,
backoff = @Backoff(delay = 1000, multiplier = 2.0)
)
public void sendNotification(Long reviewerId, String title, String message) {
fcmClient.send(reviewerId, title, message);
}
}Spring의 @Retryable 어노테이션을 사용하면 실패 시 자동으로 재시도할 수 있습니다.
구현이 간단하다는 장점이 있지만 여러가지 문제가 존재합니다.
1. 프로세스 재시작 시 데이터 손실
서버를 배포하거나 재시작하면 진행 중이던 모든 재시도가 유실됩니다. 예를 들어, 재시도 중 서버가 배포된다면 해당 알림은 평생 발송되지 않습니다.
2. 결국 신뢰성이 낮다
결국 재시도 횟수만큼 실패하면 결국 로그에만 남고 이후 재시도가 불가능합니다. 알림 유실의 확률이 여전히 존재합니다.
대안2. DB 기반 재시도
단순 재시도 시 발생하는 문제점을 해결하기 위해 알림 발송이라는 작업을 영속화할 수 있습니다.
비동기 스레드에서 즉시 알림을 보내는 대신 먼저 "알림을 발송하겠다"는 작업을 DB에 저장하고, 배치가 주기적으로 DB를 폴링하며 실제 발송하는 것입니다.
투두 인증 서비스
@Transactional
public void certifyDailyTodo(Long memberId, Long dailyTodoId, String content) {
// 인증 저장
DailyTodoCertification cert = save(memberId, dailyTodoId, content);
// 알림 발송 이벤트 발행
applicationEventPublisher.publishEvent(NotificationCreatedEvent.from(outbox));
}
이벤트 핸들러
@Component
@RequiredArgsConstructor
public class NotificationOutboxRecordListener {
private final NotificationOutboxRepository outboxRepository;
@TransactionalEventListener(phase = TransactionPhase.BEFORE_COMMIT)
public void recordMessageHandler(NotificationCreatedEvent event) {
// 알림 발송 작업을 Outbox Table에 저장
NotificationOutbox outbox = NotificationOutbox.builder()
.certificationId(event.getCertificationId())
.reviewerId(event.getReviewerId())
.status(PENDING)
.retryCount(0)
.build();
outboxRepository.save(outbox);
}
}@Component
@RequiredArgsConstructor
public class NotificationEventListener {
private final NotificationOutboxRepository outboxRepository;
private final NotificationService notificationService;
@TransactionalEventListener(phase = TransactionPhase.AFTER_COMMIT)
@Async
public void handleNotificationCreated(NotificationCreatedEvent event) {
// 알림 발송
notificationService.sendNotification(
event.getReviewerId(),
event.getTitle(),
event.getMessage()
);
// db 업데이트
outboxRepository.updateStatus(event.getOutboxId(), SUCCESS);
}
}Transactional Outbox 패턴을 구현할 때 BEFORE_COMMIT과 AFTER_COMMIT 리스너로 나눈 이유는 책임의 분리와 설계의 일관성을 확보하기 위함입니다.
핵심 도메인 로직은 이벤트 발행까지 수행하고, 부가적인 Outbox 테이블 기록은 BEFORE_COMMIT 리스너가 맡아 도메인 데이터와 원자적으로 처리되도록 보장했습니다. 또한 AFTER_COMMIT 리스너는 DB에 Outbox 기록이 확정된 후 비동기적으로 외부 시스템(FCM) 통신을 담당하도록 했습니다. 이 방식으로 도메인 로직의 응집성을 높이고 후속 작업 추가 시 확장성을 향상시킬 수 있다고 생각했습니다.
알림 전송 스케줄러
@Component
public class NotificationBatchProcessor {
@Scheduled(fixedDelay = 20000)
public void sendPendingNotifications() {
outboxRepository.findByStatus(PENDING).forEach(outbox -> {
try {
notificationService.sendNotification(
outbox.getReviewerId(),
outbox.getTitle(),
outbox.getMessage()
);
outbox.setStatus(SUCCESS);
outbox.setSentAt(LocalDateTime.now());
} catch (Exception ex) {
outbox.setRetryCount(outbox.getRetryCount() + 1);
outbox.setLastError(ex.getMessage());
if (outbox.getRetryCount() >= 3) {
outbox.setStatus(FAILED);
alertDeveloper("알림 발송 실패", outbox);
}
}
outboxRepository.save(outbox);
});
}
}이로서 기존 단순 재시도 방식의 문제를 해결할 수 있습니다.
1. 프로세스 재시작과 무관하게 재시도 가능
2. 재시도 횟수가 존재하지 않고 언젠간 발송됨 (물론 위 코드처럼 3회 이상 재시도라면 수동 대응이 필요할 수 있습니다)
한계점
알림 전송 이벤트 핸들러와 스케줄러를 보면 fcm 호출과 db 업데이트(success로 변경)을 해주고 있습니다. 따라서 이에 대해 원자성이 보장되진 않습니다. 만약 FCM 성공 후 DB 업데이트 실패를 한다면 다음 스케줄링 때 알림은 중복해서 발송될 수 있습니다.
하지만 알림 발송에서는 중복 발송보다는 유실이 훨씬 치명적이므로 중복 발송 대신 신뢰성 보장에 집중했습니다.
Transactional Outbox Pattern이란?
위에서 구현한 DB 기반 재시도 방식은 사실 Transactional Outbox라는 분산 시스템에서 데이터 일관성을 보장하기 위한 패턴입니다.
The solution is for the service that sends the message to first store the message in the database as part of the transaction that updates the business entities. A separate process then sends the messages to the message broker.
이 패턴은 데이터 변경과 메시지 발송을 원자적으로 처리하기 위해 메시지를 먼저 DB에 저장하고, 별도의 프로세스가 나중에 이를 발송합니다.
문서에서는 "DB 변경과 메시지 발송을 원자적으로 처리한다"라는 맥락으로 설명하지만, 저희 서비스의 상황과 본질적으로 같다고 생각합니다.
저희는 현재 인증 저장 (DB 작업) 과 FCM 호출 (외부 서버와의 통신) 두 가지 작업을 처리하고 있습니다. 다른 점은 서버 간 통신 상황에서 메시지 브로커에 메시지를 발행하는 통신이 아닌 비동기 스레드에서 FCM 서버와의 통신이라는 점 뿐입니다.
아웃박스 패턴이 해결하는 문제
문서에 따르면 아웃박스 패턴은 다음과 같은 상황의 문제를 해결합니다.
1. 트랜잭션 커밋 전 메시지 발행

트랜잭션 커밋 전 메시지를 발행할 경우, 커밋에 실패했을때 이미 발행된 메시지를 롤백할 수 없습니다.
2. 트랜잭션 커밋 후 메시지 발행
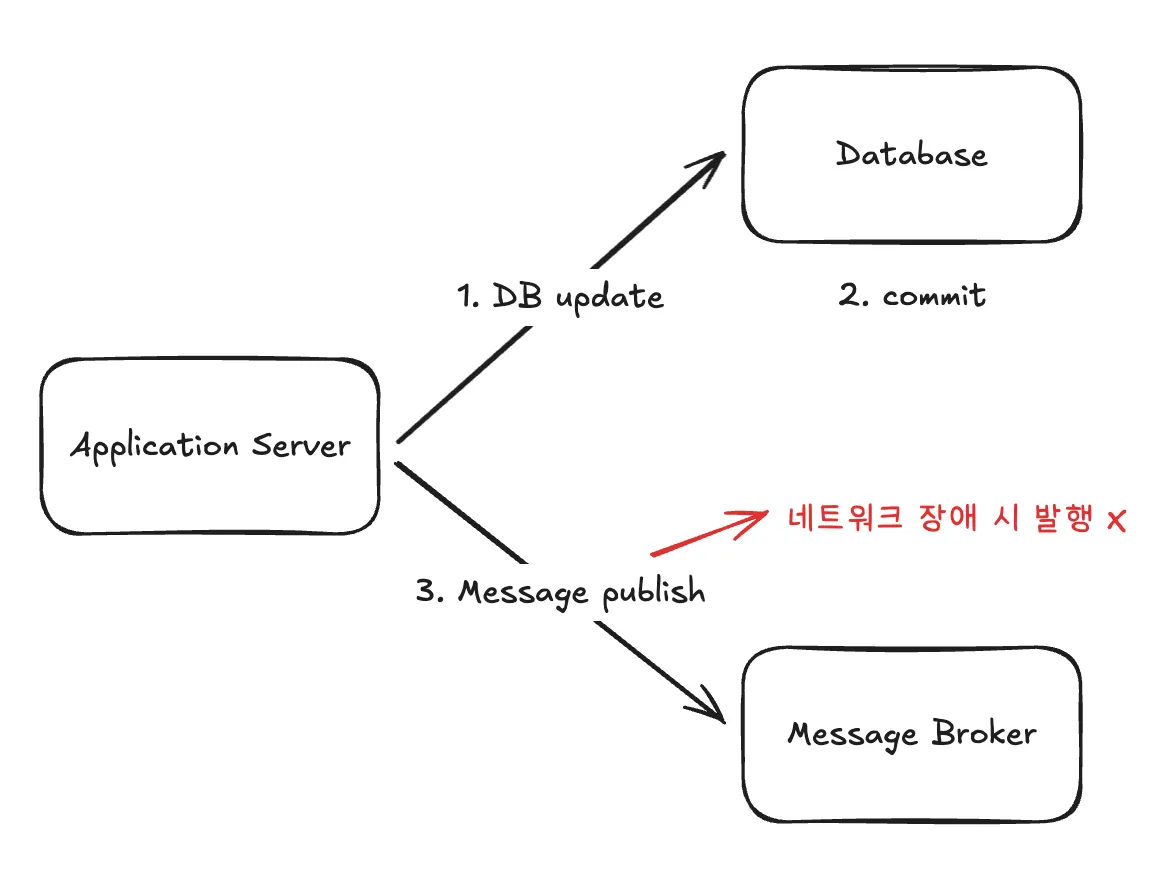
트랜잭션 커밋 후 메시지를 발행할 경우, DB update는 반영되었지만 그에 따른 메시지 발행에 실패할 수 있습니다.
이전 fcm 요청을 비동기 스레드로 분리한 후 생긴 문제와 유사합니다.
아웃박스 패턴은 메시지를 브로커에 직접 보내지 않고 먼저 DB에 저장한 후 별도의 프로세스가 나중에 가져가게 함으로써 문제를 해결합니다. 이로서 모두 같이 실패하거나, 성공하므로 원자성을 보장할 수 있습니다.

Message Relay: 별도 프로세스의 메시지 발행
Outbox에 저장된 메시지를 실제로 발송하는 것은 별도의 프로세스(Message Relay)입니다.

위에서 구현했던 Scheduler가 바로 Message Relay 역할을 수행합니다. 배치는 인증 정보 저장과는 독립적으로 작동합니다. Outbox에 저장되기만 하면, 배치가 나중에라도 반드시 발송하여 최종적 일관성을 보장합니다.
Polling Publisher 방식 선택
Message Relay의 구현 방식에는 한 가지가 더 있습니다. DB 변경 로그를 실시간으로 감지하는 Transaction Log Tailing 방식입니다.
흐름은 다음과 같습니다.
1. outbox 테이블에 insert를 하면 DB에 변경 로그가 기록됩니다. (mysql의 binlog)
2. 해당 변경을 CDC(Change Data Capture) 프로세서가 즉시 감지하고 메시지 브로커에 메시지를 발행합니다.
저는 Log Tailing 방식이 아닌 Polling Publisher 방식을 선택했습니다. 그 이유는 다음과 같습니다.
1. 인증 시 알림 발송이 실시간으로 처리될 필요가 없음
2. CDC 처리기를 추가로 구축해야 하며 인프라 비용 증가
마무리
지금까지 알림 발송 서비스에 대해 세 가지 단계를 거쳤습니다.
트랜잭션 내에서 동기 처리는 DB 저장과 알림 발송이 같은 트랜잭션 내에 있으므로 원자성이 보장되고, 알림이 정말 발송됐는지 바로 확인할 수 있었습니다. 하지만 커넥션 풀 고갈 문제가 있었습니다.
이를 해결하기 위해 비동기 방식으로 전환했습니다. DB 커넥션은 빠르게 반환되고 사용자는 빠른 응답을 받을 수 있었습니다. 하지만 비동기 스레드에서 실행하는 알림 발송의 신뢰성을 보장하기 어려웠습니다.
신뢰성을 보장하기 위해 Transactional Outbox Pattern을 도입했습니다. 사용자는 여전히 빠른 응답을 받고, DB와 알림 발송의 원자성이 보장되며, 알림 전송은 배치가 자동으로 발송합니다. 이는 알림 발송이 실시간으로 이뤄지지 않아도 된다는 비즈니스 요구사항 덕분에 가능한 선택이었으며 알림 발송을 최종적으로 보장할 수 있었습니다.
외부 API를 트랜잭션 내부에서 호출하는 것의 위험성을 이해하는 것에서 시작했지만 단순히 비동기로 분리하는 것만으로는 충분하지 않았습니다. 신뢰성을 어떻게 보장할지에 대한 고민이 필요했고, 생각보다 여러 가지 대안들이 있어 재밌었습니다.
이 과정에서 Transactional Outbox Pattern을 학습할 수 있었고 빠른 응답과 높은 신뢰성을 동시에 얻을 수 있다는 것, 그리고 마이크로서비스 아키텍처에서 널리 사용되는 이유를 조금이나마 이해할 수 있었습니다!
읽어주셔서 감사합니다.
참고 자료
https://tomcat.apache.org/tomcat-10.1-doc/config/http.html
https://microservices.io/patterns/data/transactional-outbox.html
'DND > project' 카테고리의 다른 글
| 분산 환경에서 Redisson Watchdog으로 알림 중복 발송 문제 해결하기 (0) | 2025.11.14 |
|---|